This blog will be a short one, where we’ll talk about our approach on filtering out inscrutable audios from VASR.
There are situations in Call Center Automation (CCA) pipeline where user utterances are bad. Bad here is defined by things like noise, static, silences or background murmur etc. rendering the downstream SLU systems helpless. We started with a proposal and prepare a dataset for making an ML system learn to reject these audios.
Benefits
- No more misfires from SLU side which ultimately leads to a better user experience.
- Save compute and time by skipping bad audios.
- The whole system can be used for all our audio based tasks to predict and filter out the poor ones, hence avoiding sample noise for these tasks.
Dataset
We prepared a dataset of intent tagged conversations with specially marked intents which tell us that these utterances are bad and them going further in SLU will result in errors. Also we have a sampling of non-bad utterances (tagged with regular intents) to make this a classification problem.
There are total 9928 samples of audios labelled as bad and 20000 samples labeled as good.
All the raw labels were not very useful, hence we clean and preprocess the data to finally create 2 broad categories with sub-classes.
audio-badaudio-noisy: Noisy audio.audio-silent: Silent audio.audio-talking: Background talking.hold-phone: Music from keeping on hold.
audio-good
Exploratory Data Analysis
We needed to understand the class imbalance and hence we plot a histogram representing number of samples for each class.
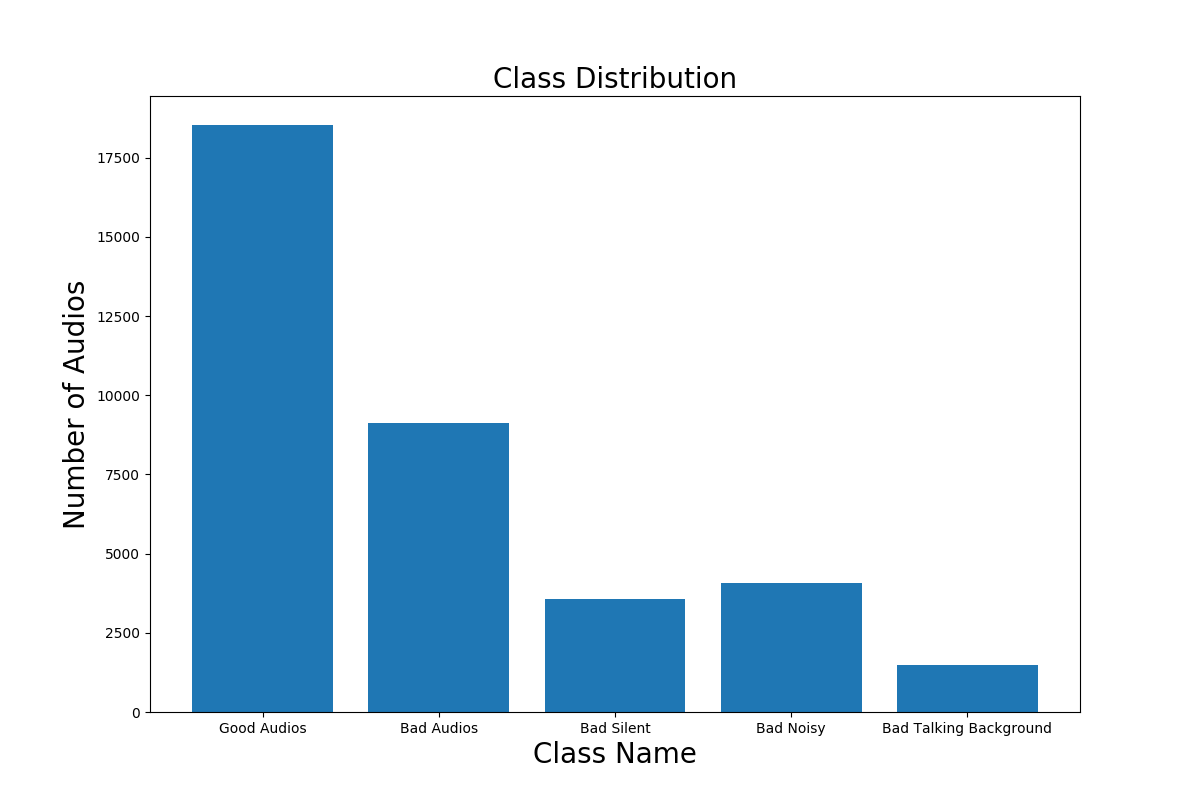
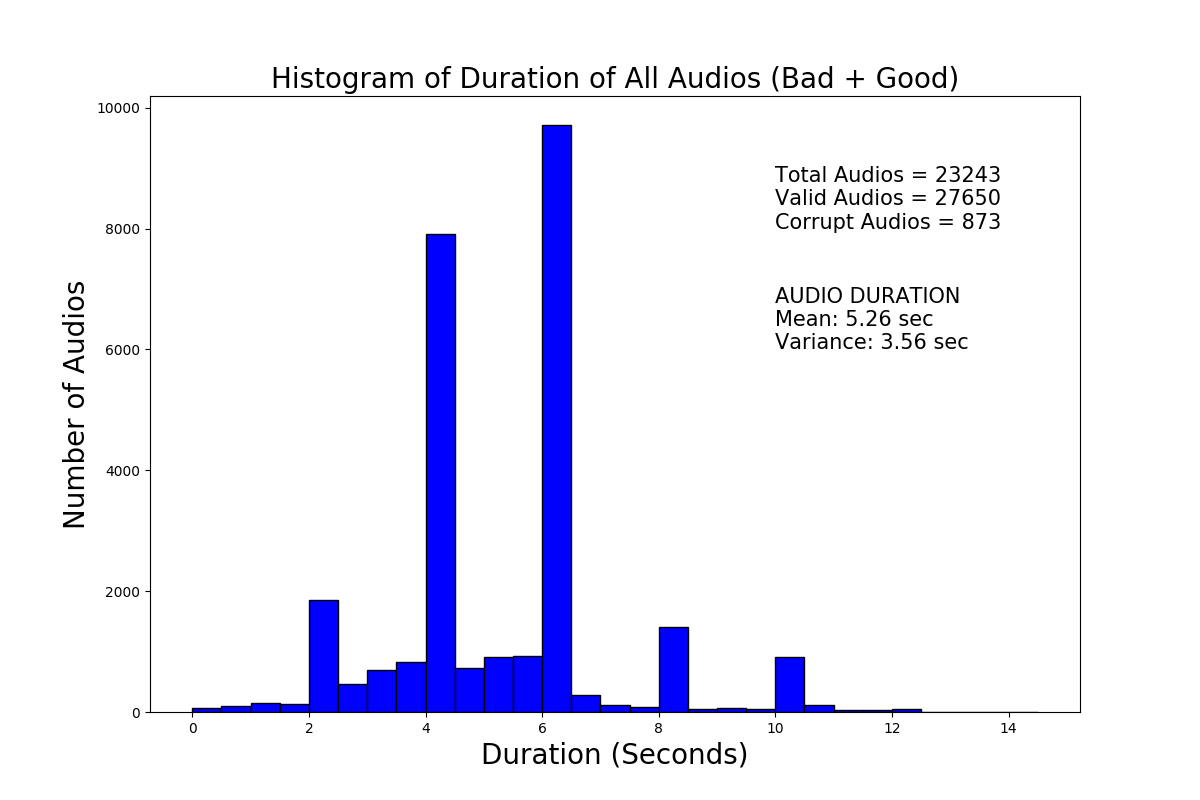
We also plot the frequency vs duration histogram plot to understand the general distribution of audio durations in the dataset. Based on the mean duration of 5.26 seconds and the peaks in the histogram, we decided to threshold our audios to 6.5 seconds. Anything less than that will be padded to 6.5 seconds and anything greater than that duration will be truncated to 6.5 seconds.
Even though we have sub-classes for audio-bad spanning different areas of
what “bad” could be, we decided to focus only on the noisy audios. Silent
Audios can be treated separately, since they do not actually require something
as complex as an ML model to classify them. We can simply use the age-old
powerful signal processing methods to filter those out with some good
confidence.
Model
If we are going to reject these bad audios then we need to do so with:
- High Precision: We should not be rejecting good audios which are perfectly interpretable and understandable.
- Low Latency: This system should have little to no latency, otherwise it will just slow down our whole VASR flow after being deployed and integrated.
- Online: The model should be capable of running in an online setting where continuous chunks of audios are fed into the system.
We used a standard audio classification pipeline to train our binary classification task.
This involves generating log-mel spectrograms and then running a Convolution Neural Network (CNN) based feature extractor on top of this fixed size spectrogram image.
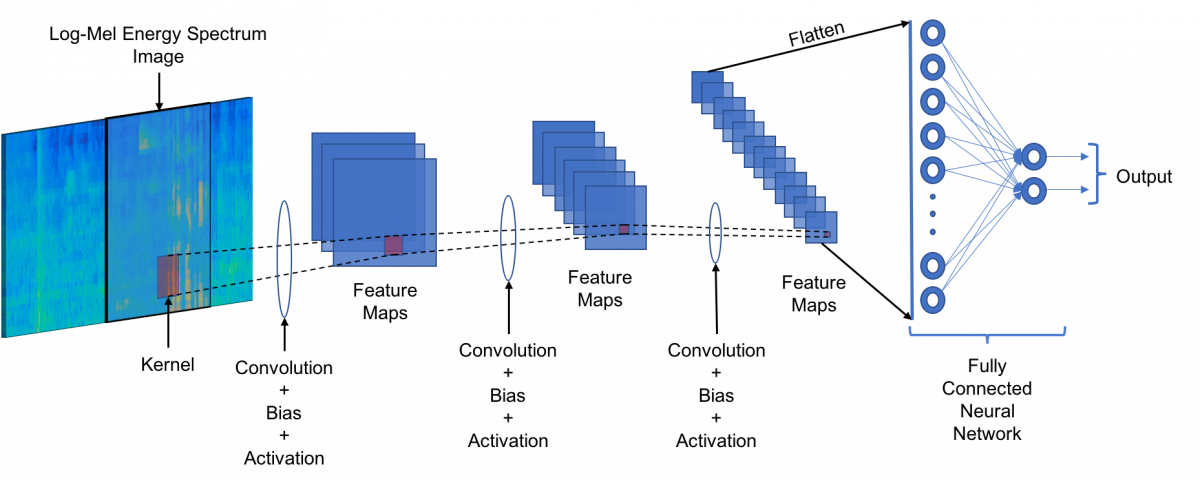
While these features (spectrograms) can be generated once after processing all
the audios in the dataset, this feature generation needs to be done on the fly
to make a model that can be used in deployment i.e given raw audios as input,
it should be able to predict the class, that was easily incorporated through a
few transforms done within the model using torch-audio.
Even though this architecture is simple, it got us an accuracy of about
87%. But it is not the accuracy we need to see, our choice of metric to
measure the performance is precision as explained earlier. We are still in
the process improving these initial baseline numbers of the model. One simple
approach for increasing the precision is to increase the threshold, trading-off
some coverage in the form of support.
Misclassification Analysis
We also do a post prediction analysis on the misclassified audios, which revealed an interesting pattern in the dataset and in the kind of audios that the model was finding hard to make predictions on.
Briefly these errors followed 3 major types which now helps to understand the places where we can make improvements.
- Type 1 (Very Short Utterance) : say 0.2 seconds in audio of 6 seconds. Due to noise in most part of such short utterance audios, our model predicts it to be noisy and not good in some occasions. This can probably be fixed with VAD which can trim the non speech segments in such short utterance audios.
- Type 2 (Long audios) : Audio duration is longer than 6.5 seconds with the speaker in latter half. Since we chose to threshold our features (log-mels) at 6.5 seconds, the latter part of the audio is basically truncated and hence such errors.
- Type 3 (Ambiguous / Wrongly Labeled) : There are samples in the dataset which are not perfectly labelled. One may say these audios are debatablem, some may find them to be bad others may think that they are ok. This type of label noise is something which needs to be tackled.
Needless to say, there are places where we can improve these results, but having a solid baseline model initially is important for incremental improvements over time and after a few iterations we finally see these models in our production systems.
That’s all for now. Stay tuned to our rss feed for updates and more.