This blog discusses some concepts from the recently published paper by members of the ML team at Skit (formerly Vernacular.ai). The paper is titled “N-Best ASR Transformer: Enhancing SLU Performance using Multiple ASR Hypotheses” and was published in ACL-IJCNLP’21.
Introduction
Voice bots in the industry heavily rely on the use of Automatic Speech Recognition (ASR) transcripts to understand the user and capture intents & entities which are then used to resolve the customer’s problem. ASR’s however are far from perfect, especially on noisy real world data and on instances with acoustic confusion. The downstream Spoken Language Understanding (SLU) components would benefit greatly if they take the ASR’s confusion into account.
Example use-case with confounding ASR transcripts (over voice):
Bot: When would you like to make the reservation ?
User (actually said): right now
ASR alternatives for given user’s speech:
- like, now
- right now
- write no
Often the downstream SLU services which act on ASR transcripts use only the most probable alternative (also called 1-best alternative), thereby leaving out a lot of other information that exists in the form of alternative probabilities. This paper presents a simple way of using the information that exists in the alternatives to get SOTA performance on a standard benchmark for a SLU system.
Types of ASR Outputs
Before we get into how to best use ASR’s confusion to increase the performance of the SLU, we discuss the different ways an ASR outputs the probable word sequence probabilities.
- N-best alternatives : this is a list of the top N alternative sentences for the given spoken utterance. These are usually ranked based on probability of occurrence.
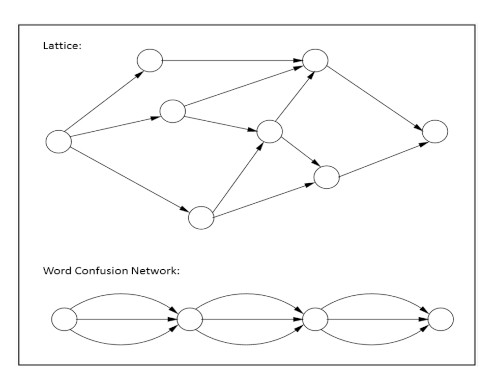
- Word lattices : As shown in the below figure, they have no a-priori structure per se. Every path from the start node to the end node represents a possible hypothesis transcript. Every transition adds a word to the hypothesis.
- Word confusion networks : They are a more compact and normalised topology for word lattices. They enforce certain constaints such that competing words should be in the same group and there by also ensure aligment of words that occur at the same time interval. Though these graphs capture lesser number of possibilities, this topology can be used to get as high recognition accuracy as using word lattices.
The transitions probabilities of both, word lattices and word confusion networks are weighted by the acoustic and language model probabilities.
Dataset
The task that is used to compare the modelling approaches is the DSTC - 2 challenge where one is required to predict intent act-slot-value triplets. Pairs of sentences i.e. a sentence whose intent is required to be predicted along with its context is given. For each sentence the top 10 best ASR alternatives are also provided.
Modelling Approach
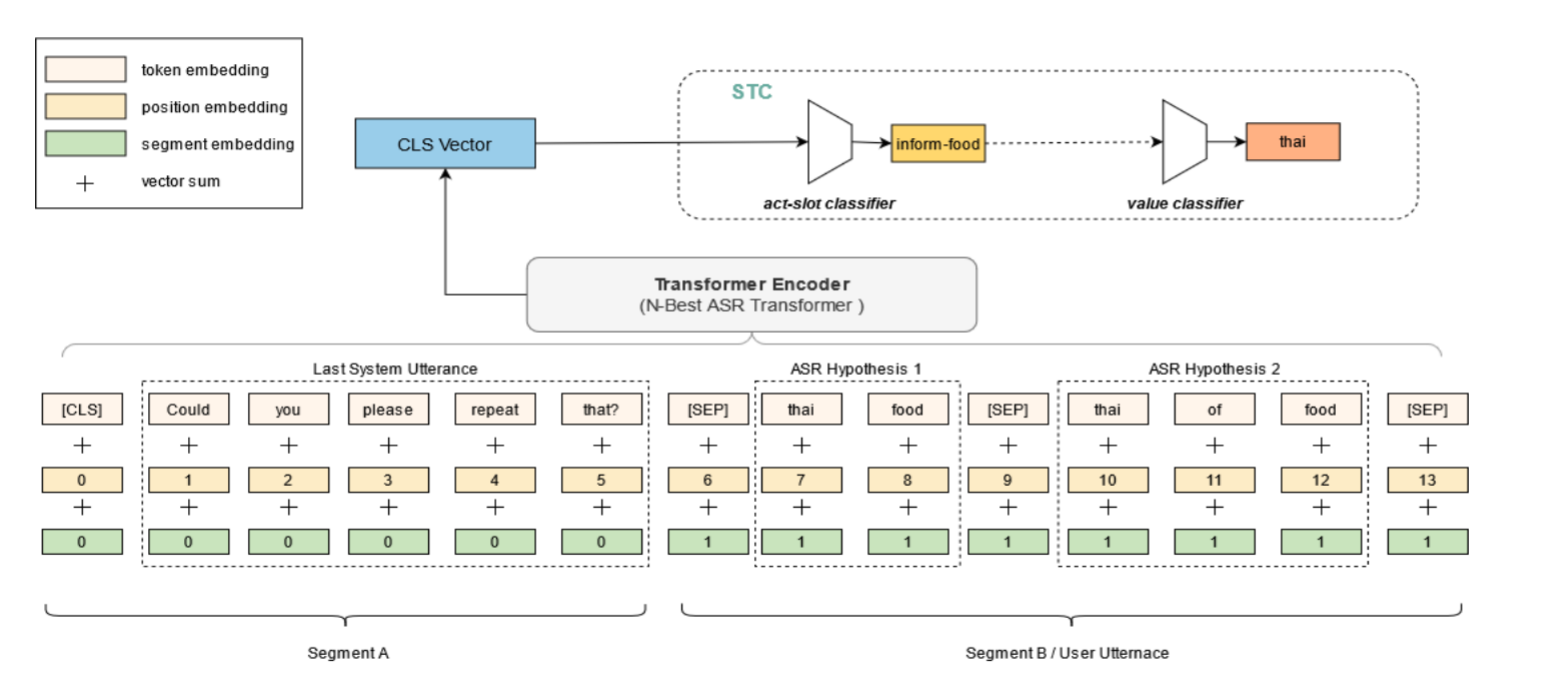
The central idea of the paper is to leverage pre-trained transformer models BERT and XLMRoBERTa and fine-tune them with a simple input representation shown below. The input consists of the ASR alternatives seperated by a seperator token concatenated with the context. A segment id (not shown below) is also used, which is used to contrast the context (in green) with the alternatives (in purple).

On top of the transformer model a semantic tuple classifier (STC) is applied to predict the act-slot-value triplets. Using this approach, we achieve a performance equivalent to the prior state-of-the-art model on DSTC-2 dataset. We get comparable F1 and SOTA accuracy. The previous SOTA model, WCN-BERT uses word confusion networks.
Here, using a simple ASR output such an N-best alternatives we get a comparable performance to the SOTA model that uses a much more informative probability graph such as a word confusion network.
Ablation Experiments
Two ablation experiments are performed. One on low data regimes and another to check the impact of the context on performance.
Low Data Regime
Here, the baseline models are compared with our approach using 5%, 10%, 20% and 50% of the training data respectively. In all these situations our approach beats SOTA by a considerable margin, proving that our training approach effectively transfer learns. We hypothesise, that this is due to the structural similarity between the input representations of the initial training of these open sourced models and the fine-turning that is done on DSTC-2 dataset. It also demonstrates that n-best alternatives are a more natural representation to fine-tune transformer models compared to word lattices or word confusion networks.
Context Dependency
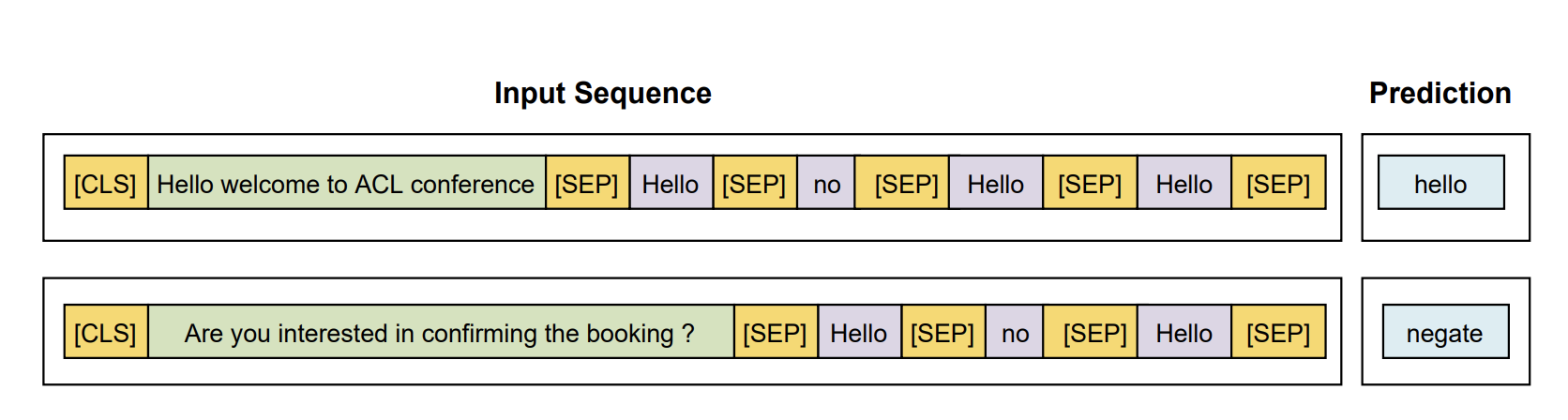
In this experiment we wanted to test the impact of adding context (last turn) to performance and to check if it is relevant at all. An improvement of around ~1.5% F1 score is obtained using context. An example situation where context is relevance is shown below. Dialog context can help in resolving ambiguities in parses and reducing the impact of ASR noise.
Lastly, this methodology can be used by users of third-party ASR APIs which do not provide word-lattice information and thereby is more accessible.
Implementation and Citation
The code for the project can be found here.
If you use our work, please cite using the following BibTex Citation:
@inproceedings{ganesan-etal-2021-n,
title = "N-Best {ASR} Transformer: Enhancing {SLU} Performance using Multiple {ASR} Hypotheses",
author = "Ganesan, Karthik and
Bamdev, Pakhi and
B, Jaivarsan and
Venugopal, Amresh and
Tushar, Abhinav",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-short.14",
doi = "10.18653/v1/2021.acl-short.14",
pages = "93--98",
}
References :
- Tür, G., Deoras, A., & Hakkani-Tür, D. (2013, September). Semantic parsing using word confusion networks with conditional random fields. In INTERSPEECH (pp. 2579-2583).