This blog post is based on the work done by Anirudh Dagar as an intern at Skit.ai
Diarization - Who spoke when?
Speaker diarisation (or diarization) is the process of partitioning an input audio stream into homogeneous segments according to the speaker identity.
Speaker diarization is the process of recognizing “who spoke when.”
In an audio conversation with multiple speakers (phone calls, conference calls, dialogs etc.), the Diarization API identifies the speaker at precisely the time they spoke during the conversation.
Below is an example audio from calls recorded at a customer care center, where the agent is involved in a one-to-one dialog with the customer.
This can be particularly hard sometimes as we’ll discuss later in the blog. Just to give an example, this audio below seems to have a lot of background talking and noise making it difficult even for a human to accurately understand speaker timestamps.
Below we have an example of an audio along with its transcription and speech timestamp tags.
Transcription: “Barbeque nation mei naa wo book kia tha ok table book kia tha han toh abhi na uske baad ek phone aaya tha toh wo barbeque nation se hi phone aaya tha mai receive nhi kar paaya toh yehi”
Diarization Tag: AGENT: [(0, 5.376), (8.991, 12.213)], CUSTOMER: [(6.951, 7.554)]
What Diarization is NOT ?
There is a fine line between speaker diarization and other related speech processing tasks.
-
Diarization != Speaker Change Detection : Diarization systems spit a label, whenever a new speaker appears and if the same speaker comes again, it provides the same label. However, in speaker change detection no such labels are given, only the boundary of change is considered for prediction.
-
Diarization != Speaker Identification : The goal is not to learn the voice prints of any known speaker. Speakers’ are not registered before running the model.
Motivation
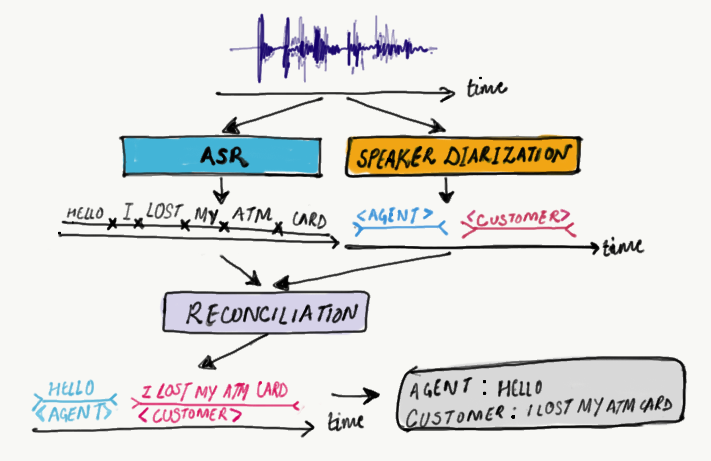
With the rise of speech recognition systems both in terms of scale and accuracy, the ability to process audio of multiple speakers is crucial and has become quintessential to understand speech today.
As illustrated in Fig 1. above, information gained through diarization helps in enriching and improving Spoken Language Understanding (SLU) based on the Automatic Speech Recognition (ASR) transcription. It can enhance the readability of the transcription by structuring the audio stream into speaker turns and, when used together with speaker recognition systems, by providing the speaker’s true identity. This can be valuable for downstream applications such as analytics for call-center transcription and meeting transcription etc.
Other than this, we at Skit.ai work on Call Center Automation (CCA) among many other speech domains, and, at the very core this is powered by our products VIVA and VASR. Information gained through diarization can be used to strengthen the VASR engine.
How?
Let me explain the goal of every customer care call support service, if you are not already aware of. The ultimate aim is to provide best in class service to the customers of the respective company. Quantitatively, measure of the service quality is based on the assessment of the AGENT’s (Call representative at customer care center) ability to disseminate relevant information to the CUSTOMER.
During the quality check phase, an AGENT’s performance is scored on mutiple parameters, such as (but not limited to):
- Whether the agent was patient enough listening to the customer or was rushing on the call
- Whether she/he was rude to the lead at any time or not
- Whether she/he used the proper language to communicate.
For such occasions, identifying different speakers in a call (“AGENT” or “CUSTOMER”) and finally connecting different sentences under the same speaker is a critical task for the assessment quality.
Speaker Diarization is the solution for those problems.
Other applications involve:
- Information retrieval from broadcast news.
- Generating notes/minutes of meetings.
- Turn-taking analysis of telephone conversations.
- Call center Data analysis
- Court houses & Parliaments.
- Broadcast News(TV and Radio)
DIHARD?
This is not 2x2=4. This is Diarization and IT IS HARD. One can say that it is one of the toughest ML problems intrinsically high on complexity, even for a human-being, in certain conditions.
But Why???
Real world audios are not always sunshine and rainbows. They come with infinite complexities. To name a few:
-
In most of the conversations, people will interrupt each other, overtalk etc., and, cutting the audio between sentences won’t be a trivial task due to this highly interactive nature.
-
Speakers are discovered dynamically. Although as you’ll see later, in our case we only have 2 speakers, a fixed number.
- Sometimes the audio is noisy:
- People talking in the background.
- The microphone picking up speakers’ environment noises (roadside noises, industrial machinery noise, music in the background etc.).
- For telephony based audios, connection may be weak at times, leading to:
- Audio being dropped/corrupted in some parts.
- Static or just some buzzing noise creeping in the conversation and finding it’s way into the audio recording.
Believe me, this is not the end of many problems for diarization!
- Maybe in a conference call with multiple speakers, even if the audio is clear, the difference can be very subtle between the speakers, and it is not always possible to identify/label the correct speaker for a particular timestamp/duration.
Ok, so that’s it?
If I have not made my point clear about the complexity of the problem, yet, then I’ll express my message through this legendary meme.

More Problems?
-
All the problems stated above are considering that preprocessing steps like VAD/SAD worked perfectly, which you may have guessed, are obviously not 100% accurate.
What is this “preprocessing step”?
Voice Activity Detection (VAD) or Speech Activity Detection (SAD) is a widely used audio preprocessing technique, before running a typical diariaztion api based on the clustering of speaker embeddings. The objective of VAD/SAD is to get rid of all non-speech regions.
Approaching the problem
Keeping in mind the complexity and hardness of the problem, multiple approaches have been devised over the years to tackle diarization. Some earlier approaches were based on Hidden Markov Models (HMMs)/ Gaussian Mixture Models (GMMs). More recently, Neural Embedding (x-vectors/d-vectors) + Clustering and End2End Neural methods have demonstrated their power.
As stated in this paper by Fujita et al., a x-vector/d-vector clustering-based system is commonly used for speaker diarization and most of our experiments are based around this approach.
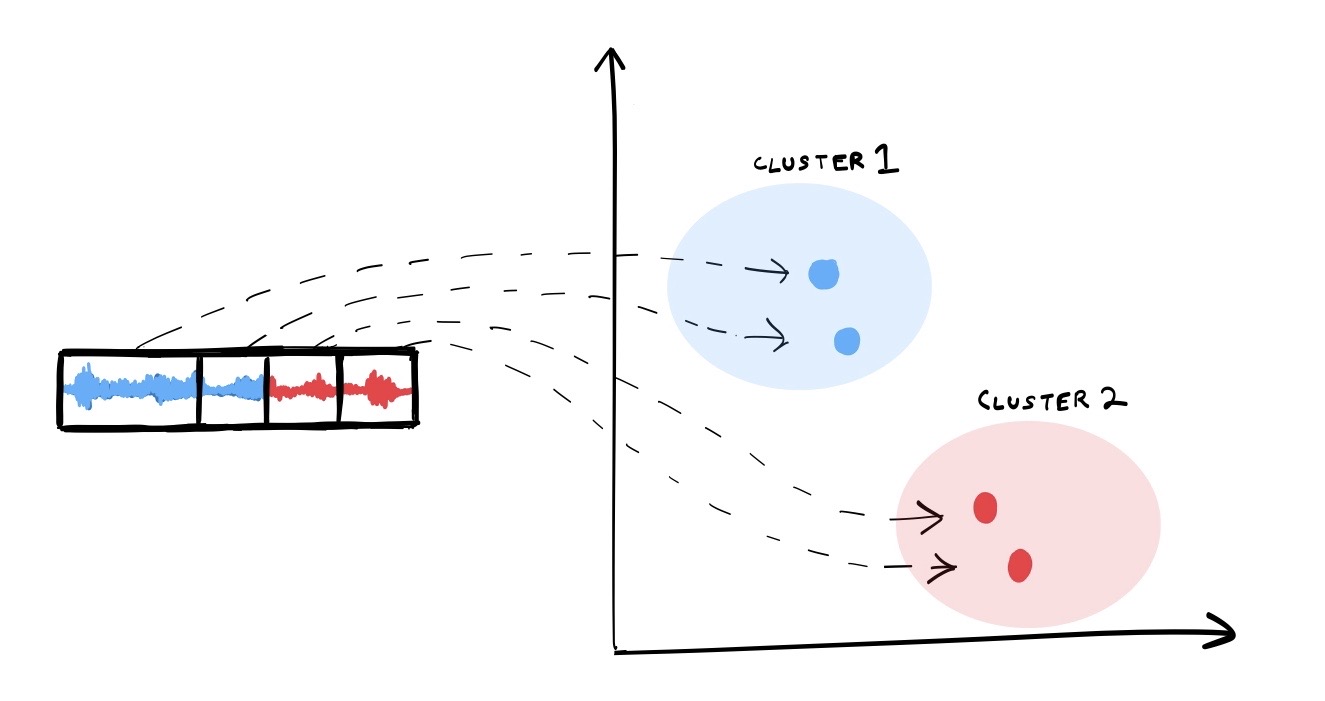
The aim of speaker clustering is to put together all the segments that belong to the same acoustic source in a recording. These don’t utilize any prior information of the speaker ID or the number of speakers in the recording. We’ll be covering a typical embedding-clustering based approach in detail in the latter sections of the blog.
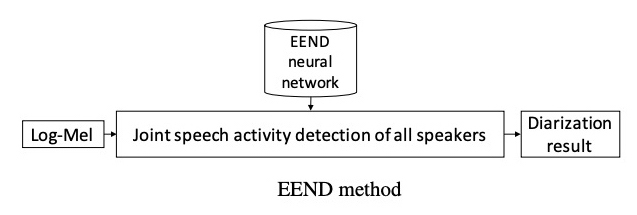
However, speaker diarization systems which combine the two tasks in a unified framework are gaining popularity in recent times. Fig 4 visually summarizes the End2End idea. Due to the increased amounts of data being avaialable, joint End2End modeling methods are slowly taking over older approaches across ML domains, alleviating the complex preparation processes involved earlier.
One example is EEND: End2End Neural Diarization by Fujita et al. proposed recently showing some promise in regards to solving these complex steps jointly.
Defining Our Problem
We need to answer the question “What should be a robust diarization system?” before moving forward. We decided to try out multiple approaches and model experiments explained in the sections below.
Our model should be powerful enough to capture global speaker characteristics in addition to local speech activity dynamics. A systems, that is able to accurately handle highly interactive and overlapping speech specifically in the telephony call audios conversational domain, while being resilient to variation in mobile microphones, recording environment, reverberation, ambient noise, speaker demographics. Since we have a more focused problem, for evaluating customer care center call audios, the number of speakers for our use case is fixed at two i.e “AGENT” and “CUSTOMER” for each call, we need to tune our model for the same.
Method

-
VAD — We employ WebRTC VAD to remove noise and non speech regions during our experiments. Raw audios are split into frames with specific duration (30 ms in our case). For each input frame, WebRTC generates output 1 or 0, where 1 denotes speech and 0 denotes nonspeech. An optional setting of WebRTC is the aggressive mode, an integer between 0 and 3. 0 is the least aggressive about filtering out nonspeech while 3 is the most aggressive. These VAD/SAD models have their own respective struggles with and set of problems.
-
Embedder — Resemblyzer allows you to derive a high-level representation of a voice through a deep learning model (referred to as the voice encoder). Given an audio file of speech, it creates a summary vector of size 256 (embedding) that summarizes the characteristics of the voice spoken.
-
Clustering — We cluster the segment wise embedding using a simple K-Means to produce diarization results and determine the number of speakers with each speakers time stamps.
-
Resegmentation - Finally, an optional supervised classification step may be applied to actually identity every speaker cluster in a supervised way.
Evaluation Metrics
To evaluate the performance or to estimate the influence of errors on the
complete pipeline, we use the standard metrics implemented in
pyannote-metrics.
We also need to account for the fact that these time-stamps are manually
annotated by data-annotators and hence cannot be precise at the audio sample
level. It is a common practice in speaker diarization research to remove a
fixed collar around each speaker turn boundary from being evaluated using our
metric of choice. A 0.4sec collar would exclude 200ms before and after the
boundary.
Diarization error rate (DER) is the de facto standard metric for evaluating and comparing speaker diarization systems. It is measured as the fraction of time that is not attributed correctly to a speaker or non-speech.
The DER is composed of the following three errors:
False Alarm: It is the percentage of scored time that a hypothesized speaker is labelled as a non-speech in the reference. The false alarm error occurs mainly due to the the speech/non-speech detection error (i.e., the speech/non-speech detection considers a non-speech segment as a speech segment). Hence, false alarm error is not related to segmentation and clustering errors.
Missed Detection: It is the percentage of scored time that a hypothesized non-speech segment corresponds to a reference speaker segment. The missed speech occurs mainly due to the the speech/non-speech detection error (i.e., the speech segment is considered as a non-speech segment). Hence, missed speech is not related to segmentation and clustering errors.
Confusion: It is the percentage of scored time that a speaker ID is assigned to the wrong speaker. Confusion error is mainly a diarization system error (i.e., it is not related to speech/non-speech detection.) It also does not take into account the overlap speeches not detected.
\[\text{DER} = \frac{\text{false alarm} + \text{missed detection} + \text{confusion}}{\text{total}}\]Resegmentation
As stated earlier, speaker diarization consists of automatically partitioning an input audio stream into homogeneous segments (segmentation) and assigning these segments to the same speaker (speaker clustering). Read more about segmentation here.
Is it possible to resegment these assignments, post clustering, to achieve an improved lower DER?
This is exactly the job of a resegmentation module. Simply put, we had a condition to be improved, a difficulty to be eliminated, and a troubling question that existed.
If yes, in what scenarios this optional (Resegmentation) module helps?
Before going ahead with resegmentation, we needed meaningful understanding and deliberate investigation of the predictions to answer the above question.
We brainstormed on this particular section involving post-processing of predictions in the diarization pipeline. After analysis and comparisons of predicted annotations made to the true annotations, our system, though good (with DER=0.05), was possibly facing an issue.
We were hit by something called oversegmentation, which can be seen in figure 6 below.
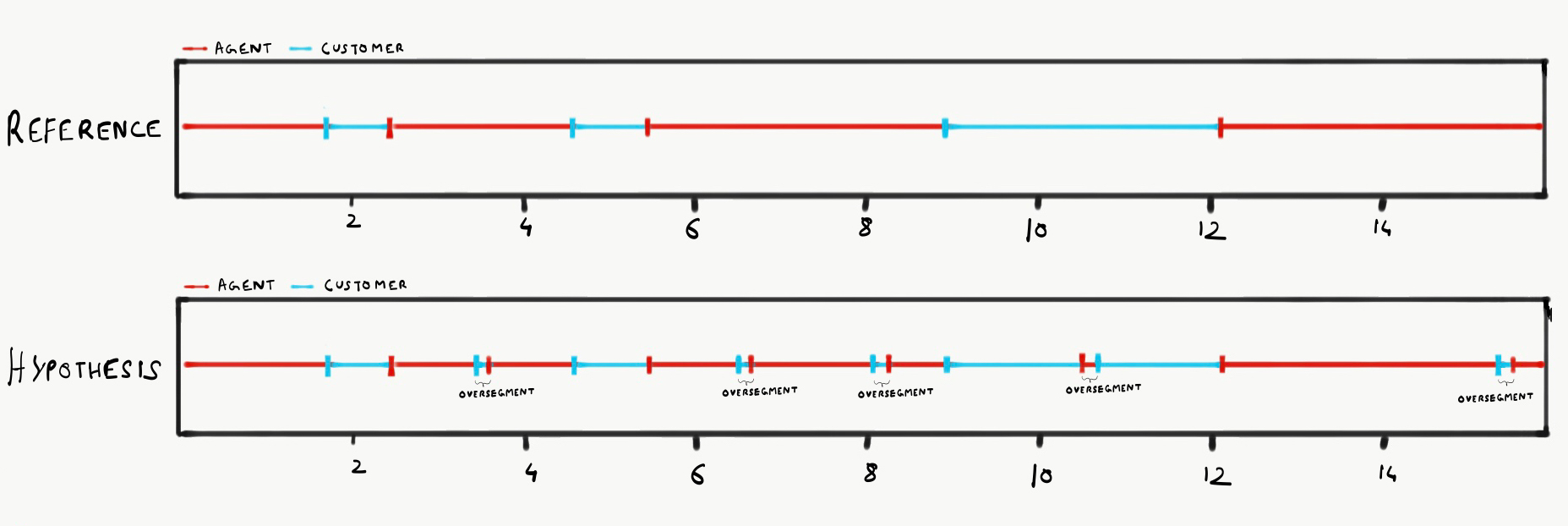
To fix this problem and in the process making our system more robust, we tried multiple experiments tweaking the resegmentation module.
- Standard Smoothing: This is a simple annotation post processing
smoothing functionto solve the abrupt annotated segments (oversegmented regions) by merging these items smaller than or equal to the threshold (duration less than 0.2 seconds) with neighbouring annotation. We instantly got a 1% boost in DER (0.04) after smoothing.
Our initial hunch about oversegmentation based on the analysis was now supported by results from this simple exercise. This made us think about a few more questions:
- Can we do even better?
- Can we use the labels and supervise the resegmentation module learning this smoothing function at the very least?
- Are there some other errors in the predictions which we may have overlooked, but probably a learned resegmentation model captures?
- Can we leverage clustering confidences to improve the resegmentation module?
Aiming to answer the above questions, we came up with a Supervised Resegmentation Sequence2Sequence model.
-
Supervised Seq2Seq Resegmentation: The goal of the model as shown below is to learn a mapping from the initial predictions to the ground truth sequence based on supervised training.
Resegmentation Goal PREDICTIONS GROUND TRUTH [A, A, A, A, B, A, A, B, B, B ....] -> [A, A, A, A, A, A, A, B, B, B ....] where A : Speaker 1 B : Speaker 2 each label represents fixed duration of 400ms in our annotations.To achieve such a mapping we worked on a simple Seq2Seq LSTM based model. We also enriched this model with information of cluster confidences after tweaking our Embedding+Clustering pipeline to do a soft clustering, i.e. return cluster scores based on the distance of each point in the cluster from the centroid along with the clustered predictions.
Overall all the above steps regarding a supervised resegmentation model were completely experimental and based on a few ideas. We are yet to achieve convincing results based on this approach but I thought it would be nice to mention this cool experiment :). Providing more resegmentation sequences for training could definitely and we also try to tackle diarization with limited data. See here
UIS-RNN
To explore more supervised methods, we also experimented with Fully Supervised Speaker Diarization or the UIS-RNN model, the current state of the art neural system for Speaker Diarization. Converting data to UIS Style format involves a set of preprocessing steps similar to what we had to for our supervised resegmentation model. More on the official UIS-RNN Repo.
But a caveat with UIS-RNN is that it requires huge amounts of data to form a convincing hypothesis after training. On realizing the limited amount of tagged data we had, we worked on simulating datasets for Speaker Diarization which in itself comes with some challenges.
Simulated Data Generation
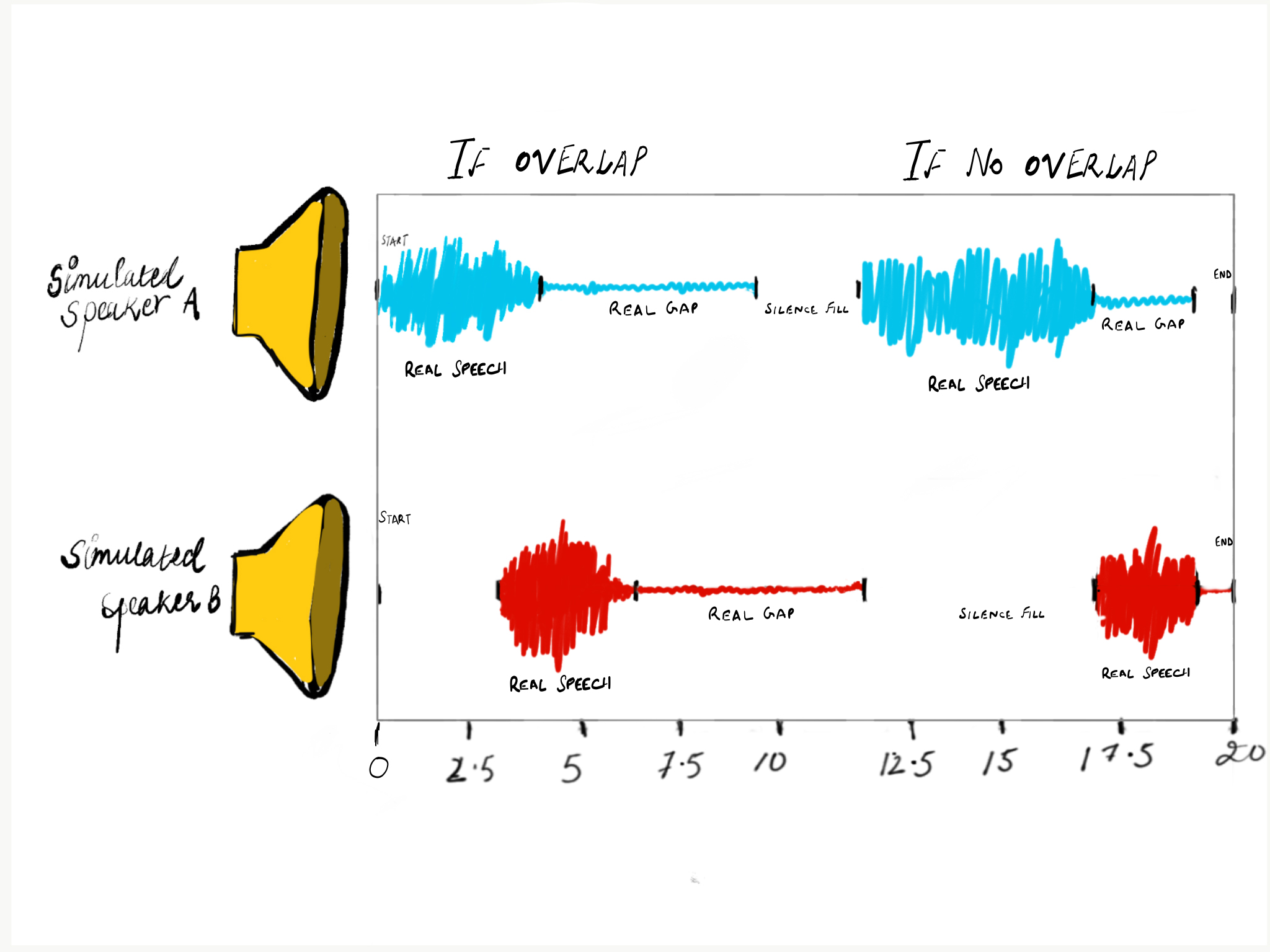
We started with a large number of dual channel audio calls as a requirement for generating this Speaker Diarization Dataset.
These dual channel audios were then split and saved into mono channel audio files. The key idea is that each mono channel contains one speaker and if we are able to combine these mono channeled audios compunded with known timestamps of speakers, we can then possibly recreate the audios which are potentially useful for Supervised Speaker Diarization.
Steps as shown in Fig 7:
-
Split dual channel audio calls into mono channel audios.
- Running Webrtc VAD on the mono channels:
- Aggressive : Speech Regions.
- Mild : Invert to get Gap Regions
- Compute statistics in real audios: This step is required for us to understand the dynamics of overlaps and silences in a call on avergae. We compute the following ratios:
- \[\text{Silence Ratio} = \frac{\text{Duration of Silences}}{\text{Total Duration}}\]
- \[\text{Overlap Ratio} = \frac{\text{Duration of Overlapping Utterances}}{\text{Total Duration}}\]
- Combination of Speech from A and B with timestamps. At the same time we needed to add real Gaps/Silence fills and Overlaps (interrupts and overtalking) to mimic real world call audios which are highly interactive.
To control the amount of overlap in data-generation, we used 2 parameters mainly.
scale_overlap: This allowed us to control the maximum possible duration of overlap and was set based on the stats gathered in step 3.bias_overlap: This allowed us to control the percentage or probability if there is an overlapping segment. Eg: setting bias_overlap to 0.75 will give 33% chance each time to add overlap.
- Dump tagged speaker timestamps and simulated audios.
That’s all for now, and we’ll end this blog here. Stay tuned to our rss feed for updates.
Until next time, Signing Off!
References
- Deep Self-Supervised Hierarchical Clustering for Speaker Diarization
- Joint Speech Recognition and Speaker Diarization via Sequence Transduction
- WebRTC VAD
- DIHARD II is Still Hard: Experimental Results and Discussions from the DKU-LENOVO Team
- PyAnnote Audio
- Resemblyzer
- Awesome Diarization
- Robust Speaker Diarization for Meetings
- Generalized End-To-End Loss For Speaker Verification
- Fully Supervised Speaker Diarization